
The OpenText Content Server Admin's Most Dreaded Words: Content Server Down!
We continually get inquiries from our Customers and Partners as to how solutions from Syntergy can assist them in the areas of Disaster Recovery (DR), High Availability (HA) and Continuity of Operations (COOP) for their On-Premise or IaaS-based (OpenText Cloud, Azure, Amazon, etc.) Content Server environments.
The common themes we see in our customer's Content Server deployments include:
- Content Server is now mission critical to organizations and the use cases as to how an organization uses Content Server are many:
- Collaboration Platform
- Document Management/Records Management for long term storage
- Global Intranets, Extranets and external facing websites
- Content Management for ERP systems such as SAP and Oracle
- Static publishing for content delivery to critical operations centers, safety and emergency management systems, corporate policies, SEC filings, procedures and best practices content
- Business Process Automation, Content Authoring, Approval and Promotion
- Customer Service applications which include frequently asked questions (FAQs)
- Increasingly complex deployments with integration to other data sources e.g. ERP, CRM and Search Content sources
- Multiple applications for all businesses across an organization
- Exponentially growing metadata and content
- Implementing storage strategies to efficiently manage growth of content and compliance requirements
- Deployment of complex workflows
- Custom solutions and integration with other data sources
- Global user communities
- Complex Content Server governance policies and permission management
- Information sharing with outsourced partners and customers
As a result, the business users of Content Server are now defining Service Level Agreements (SLAs) with IT departments that require:
- Content Server to be 100% available during planned and un-planned outages
- Read/Write access to the secondary Content Servers when the primary server is not available
- Content Server data needs to exist in a different geography or multiple geographies for extra resiliency and risk management
- Content Server needs to be easily testable for DR audits without impacting the production system
- Very short Recovery Time Objective (RTO) and Recovery Point Objective (RPO) e.g. less than hour or even down to minutes
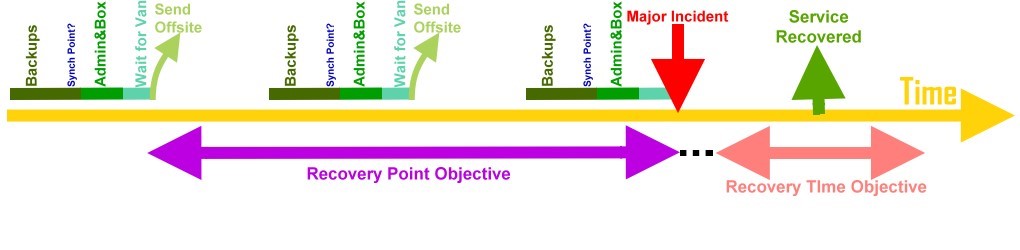
RTO = Recovery Time Objective
The recovery time objective (RTO) is the duration of time and a service level within which a business process must be restored after a disaster (or disruption) in order to avoid unacceptable consequences associated with a break in business continuity.
RPO = Recover Point Objective
A recovery point objective (RPO) is defined by business continuity planning. It is the maximum tolerable period in which data might be lost from an IT service due to a major incident. The RPO gives systems designers a limit to work to. For instance, if the RPO is set to four hours, then in practice, offsite mirrored backups must be continuously maintained and a daily offsite backup on tape will not suffice. Care must be taken to avoid two common mistakes around the use and definition of RPO.
Historically for the earlier implementations of Content Server, for unplanned outages, the RPO (amount of data loss) time has been 24 hours and a range of 24 to 72 hours for RTO (how long it will take to recover Content Server).
For planned Content Server outages e.g. rolling system software upgrades to Windows, SQL Server, Content Server and software integration the RTO historically has been anything from 12-24 hours.
This is now a dilemma for IT departments and many organizations are not meeting their defined SLAs and COOP requirements. This is impacting the organization's business from a cost perspective - loss of revenue, compliance, risk management issues and time consuming or failed DR Audit exercises.
Industry "experts" continue to recommend the traditional out-of-the-box (OOTB) methods or "Active/Passive" solutions which are either Windows Server or database based (e.g. SQL Server) and not Content Server based. There are limitations with these approaches and they are not meeting most organizations Content Server SLAs.
In our opinion, with traditional OOTB methods, VM replication is the best way to keep a clone of your Content Server. However, there are limitations with the traditional OOTB solutions:
- Content Server External File System (EFS) needs to replicated separately to the DR location impacting RPO
- There are many OOTB database replication options:
- Database Clustering - An expensive and older approach and technology
- For Microsoft databases, SQL Log Shipping (fairly old approach but most commonly used) - Complex, database unusable until recovery and logs applied impacting RTO
- Mirroring - Use snap shots of SQL but massive reliance on snap shots; Limited WAN support; requires high speed networks with low latency. Failover to Content Server is not automatic and manual scripts have to be run as well as security settings have to be created precisely for services running on production servers
- New solutions from Microsoft and Oracle (e.g. Microsoft SQL Always On Availability Groups (AOAGs)) can handle multiple copies of databases and failover is automatic. These solutions work best with synchronous communications, but the limitation is bandwidth for cross data centers e.g.1 GB of bandwidth with millisecond latency is a requirement which typically is not available for a WAN. AOAGs is well positioned as a redundancy solution for a single Content Server, but it designed to be run within a single data center. This doesn't help your users if connectivity to the data center goes down or if they're remote and need local access to content. You also lose the ability to share content across different domains, user authentication models, or to remap structure and restrict what is synchronized for remote users. You still have to deal with the issue of continually replicating the Content Server EFS impacting RPO.
- VM Replication - Although the best approach, there are limitations, especially if you are restoring to the same server. These configurations are also best served when "very close" in geography to your production Content Server. i.e. if you clone a VM, it needs to have the same network configuration, or requires scripts to touch it up at the destination. Also note that cloning a virtual machine does not protect you fully (e.g. the Operating System layer could get corrupted - i.e. a corrupted driver, or hotfix and then this corruption is cloned to the target). Your target Content Server also suffers data corruption, but this is explicitly the way these techniques work!
Syntergy Recommendations for a Complete Continuity of Operations Environment
Content Server operates at distinct layers, each with their own operational requirements. When planning for a complete DR/HA strategy for your Content Server environment, our recommendations would be to have redundancy built in your production system as a first line of defense (e.g. multiple WFE's, RAID etc.). Also have a redundant database as part of this architecture where you can have two SQL servers and multiple WFE's all ready and waiting to be used in case a layer fails. WFE's are also easy to point to a different database.
Because of the limitations inherent in Content Server high availability options, IT Departments are now demanding and implementing application-layer replication technologies such as the Syntergy Replicator to achieve their Content Server SLAs.
These technologies operate at the Content Server application program interface (API) level to provide a complete Content Server view and better capabilities to simplify the recovery process - looking for new documents and content within a Content Server library, and then sending that content to another active server in a different location. Every time a document is added or modified in Content Server, a copy of that document is then replicated to the multiple servers within the organization. As these technologies replicate at the application level, there is no risk of corrupting your secondary servers. Application based replication such as Syntergy Replicator work on individual content and have the advantage that the standby Content Server is continuously in recovery mode, so in case of a planned or un-planned outage it is very easy and fast to enable the standby Content Server as the new primary. Once your primary is back up and running, all the incremental changes in your secondary server are automatically queued back to the primary server.
Our customers who deploy the Syntergy Replicator to meet their SLAs have the following goals:
- Need very high up-times for Content Server - it's so business-critical it can never go down
- Multiple standby Content Servers need to be deployed for extra resiliency in multiple geographies
- Separation in geography for DR servers - Have datacenters more than 300 miles apart and hence cannot use synchronous database mirroring or other technologies described above due to technical limitation e.g. 1 GB of bandwidth with millisecond latency or at a minimum less than 10ms latency is required
- Active-Active/Hot-Hot 24x7x365 Content Server availability:
- RTO - Typically minutes to zero
- RPO - Typically minutes to zero
- Hot/Live during recovery
- Heterogeneous setup - Content Servers do not have to be identical in terms of Operating System version, SQL, Content Server version e.g. support for cross versions of Content Server - Content Server 10 <-> Content Server 10.5 or Content Server 10.5 <-> Content Server 16 replication
- Data is incrementally transferred back to production server from DR server after a failover -Read/Write operations are supported on DR server
- Easily testable for Audits/DR exercises without impacting production server
- Need to perform rolling upgrades on production server (patching Windows, SQL, Content Server) while users are accessing secondary server for "Continuity of Operations"
- No minimum WAN bandwidth requirements and supports datacenter locations more than 300 miles apart for extra resiliency
- Granular Replication Requirements - only certain applications need to be selected for replication to the secondary location. Content can be identical or a subset as not all applications may have the same SLAs
- External File Systems (EFS) technologies compatibility. Traditional OOTB, 3rd party Active/Passive DR solutions only back up database content, missing any documents (blobs) that are in the EFS